Note
Go to the end to download the full example code
Approximate Control Variate Allocation Matrices
Optimizing and constructing PACV estimators requires estimating \(\covar{Q_0}{\Delta}\) and \(\covar{\Delta}{\Delta}\) which depend on the statistical properties of the models being used but also on the sample alloaction how independent sample sets are shared among the sample sets \(\rvset_\alpha\text{ and }\rvset_\alpha^*\).
For example, when computing the mean of a scalar model when the covariance between models is given by \(\mat{C}\) and the first row of \(\mat{C}\) is \(\mat{c}\) then
and
where \(\circ\) is the Haddamard (element-wise) product.
The implementation of PACV uses allocation matrices \(\mat{A}\) that encode how independent sample sets are shared among the sample sets \(\rvset_\alpha\text{ and }\rvset_\alpha^*\).
For example, the allocation matrix of ACVMF using \(M=3\) low-fidelity models (GMF with recursion index \((0,0,0)\)) is
An entry of one indicates in the ith row of the jth column indicates that the ith independent sample set is used in the corresponding set \(\rvset_j\) if j is odd or \(\rvset_j^*\) if j is even. The first column will always only contain zeros because the set \(\rvset_0^*\) is never used by ACV estimators.
Note, here we focus on how to construct and use allocation matrices for ACVMF like PACV estimtors. However, much of the discussion carries over to other estimators like those based on recursive difference and ACVIS.
The allocation matrix together with the number of points \(\mat{p}=[p_0,\ldots,p_M]^\top\) in the each independent sample set which we call partitions can be used to determine the number of points in the intersection of the sets \(\rvset_\alpha\text{ and }\rvset_\beta\), where \(\alpha\text{ and }\beta\) may be unstarred or starred. Intersection matrices are used to compute \(\covar{Q_0}{\Delta}\) and \(\covar{\Delta}{\Delta}\). The number of intersection points can be represented by a \(2(M+1)\times 2(M+1)\) matrix
Defining
each entry of B can be computed using
where
Note computing \(\covar{Q_0}{\Delta}\) and \(\covar{\Delta}{\Delta}\) also requires the number of samples \(N_\alpha\), \(N_{\alpha^*}\) in each ACV sample set \(\rvset_\alpha,\rvset_\alpha^*\) which can be computed by simply summing the rows of S or more simply extracting the relevant entry from the diagonal of B. For example
Finally, to compute the computational cost of the estimator we must be able to compute the number of samples per model. The number of samples of the ith
where \(\chi[A_{2i,k}+A_{2i+1,k}]=1\) if \(A_{2i,k}+A_{2i+1,k}>0\) and is zero otherwise.
Using our example, the intersection matrix is
So summing each column of S we have
And
The first row and column are all zero because \(\rvset_0^*\) is always empty.
As an example the thrid entry from the right on the bottom row corresponds to \(B_{75}=N_{3\cup 2}\) which is computed by finding the rows in R that have non zero entries which are the first three rows. Then the \(B_{75}\) is the sum of these rows in the 5 column of S, i.e. \(2+3+4=9\).
Examples of different allocation matrices
The following lists some example alloaction matrices for the parameterically defined ACV estimators based on the general structure of ACVMF.
MFMC \((0, 1, 2)\)
\((0, 0, 1)\)
\((0, 0, 2)\)
\((0, 1, 1)\)
How to construct ACVMF like allocation matrices
The following shows the general procedure to construct ACVMF like estimators for a recursion index
As a concrete example, consider the recursion index \(\gamma=(0, 0, 1)\).
First we set \(A_{2\alpha+1,\alpha}=1\) for all \(\alpha=0,\ldots,M\)
E.g. for (0,0,1)
We then set \(A_{2\alpha,\gamma_\alpha}=1\) for \(\alpha=1,\ldots,M\). For example,
And finally because ACMF always uses all independent partitions up to including \(\gamma_\alpha\) we set \(A_{i,k}=1\), for \(k=0,\ldots,\gamma_\alpha\) and \(\forall i\). For example
The following can be used to plot the allocation matrix of any PACV estimator (not just GMF). Note we load a benchmark because it is needed to initialize the PACV estimator, but the allocation matrix is independent of any benchmark properties other than the number of models it provides
import matplotlib.pyplot as plt
from pyapprox.benchmarks import setup_benchmark
from pyapprox.multifidelity.factory import get_estimator, multioutput_stats
benchmark = setup_benchmark("tunable_model_ensemble")
model = benchmark.fun
stat = multioutput_stats["mean"](benchmark.nqoi)
stat.set_pilot_quantities(benchmark.covariance)
est = get_estimator("grd", stat, model.costs(), recursion_index=(2, 0))
ax = plt.subplots(1, 1, figsize=(8, 6))[1]
_ = est.plot_allocation(ax)
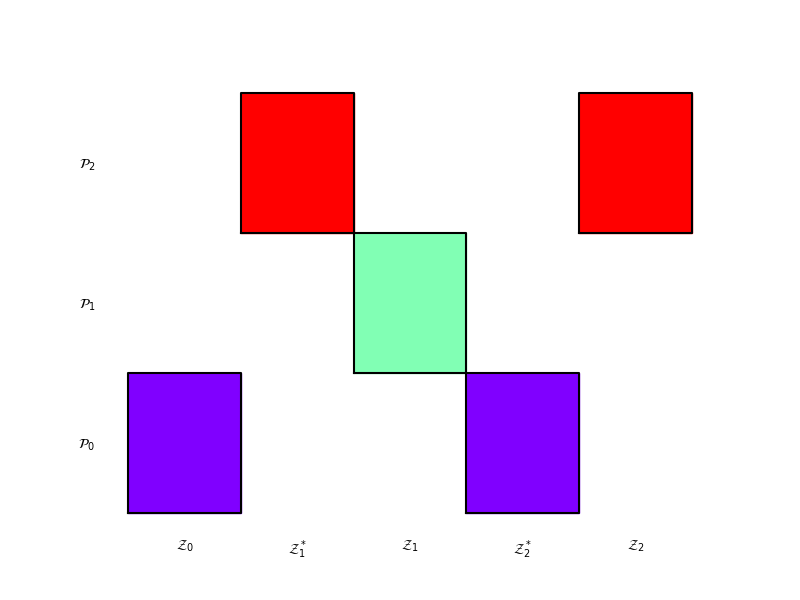
The different colors represent different independent sample partitions. Subsets \(\rvset_\alpha\text{ or }\rvset_\alpha^*\) having the same color, means that the same set of samples are used in each subset.
Try changing recursion index to (0, 1) or (2, 0) and the estimator from “gis” to “gmf” or” grd”
Evaluating a PACV estimator
Allocation matrices are also useful for evaluating a PACV estimator. To evaluate the ACV estimator we must construct each independent sample partition from a set of \(N_\text{tot}\) samples \(\rvset_\text{tot}\) where
We then must allocate each model on a subset of these samples dictated by the allocation matrix. For a model index \(\alpha\) we must evaluate a model at a independent partition k if \(A_{2\alpha, k}=1\) or \(A_{2\alpha+1, k}=1\). These correspond to the sets \(\rvset_{\alpha}^*, \rvset_{\alpha}\). We store these active partitions in a flattened sample array for each model ordered by increasing partition index, which is passed to each user. E.g. if the partitions 0, 1, 3 are active then we store \([\rvset_{0}^\dagger, \rvset_{1}^\dagger, \rvset_{3}^\dagger]\) where the dagger indicates the samples sets are associated with partitions and not the estimator sets \(\rvset_{\alpha^*}, \rvset_{\alpha}\).
The user can then evaluate each model without knowing anything about the ACV estimator sets or the independent partitions.
These model evaluations are then passed back to the estimator and internally we must assigne the values to each ACV estimator sample set. Specifically for each model \(\alpha\), we loop through all partition indices k and if \(A_{2\alpha,k}=1\) we assign \(\mathcal{f_\alpha(\rvset^\dagger_k)}\) to \(\rvset_{\alpha^*}\) similarly if \(A_{2\alpha+1,k}=1\) we assign \(\mathcal{f_\alpha(\rvset^\dagger_k)}\) to \(\rvset_{\alpha}\).
Total running time of the script: ( 0 minutes 0.037 seconds)