Usage
This section covers day-to-day interaction patterns for users who need to read, write, pin, and synchronize state.
It focuses on the currently deployed general interface shape used by sync-services.
Graphical Interface
Section titled “Graphical Interface”The general compose network exposes three primary web clients and one filesystem-oriented service: Explorer (/explorer/), Workbench (/workbench/), Gateway (/docs plus /api/v1/...), and File System (SMB).
Together they cover the full operator/developer loop: inspect data, make changes, verify outcomes, mount journal state into ordinary file tools, and convert successful workflows into repeatable API calls.
Explorer
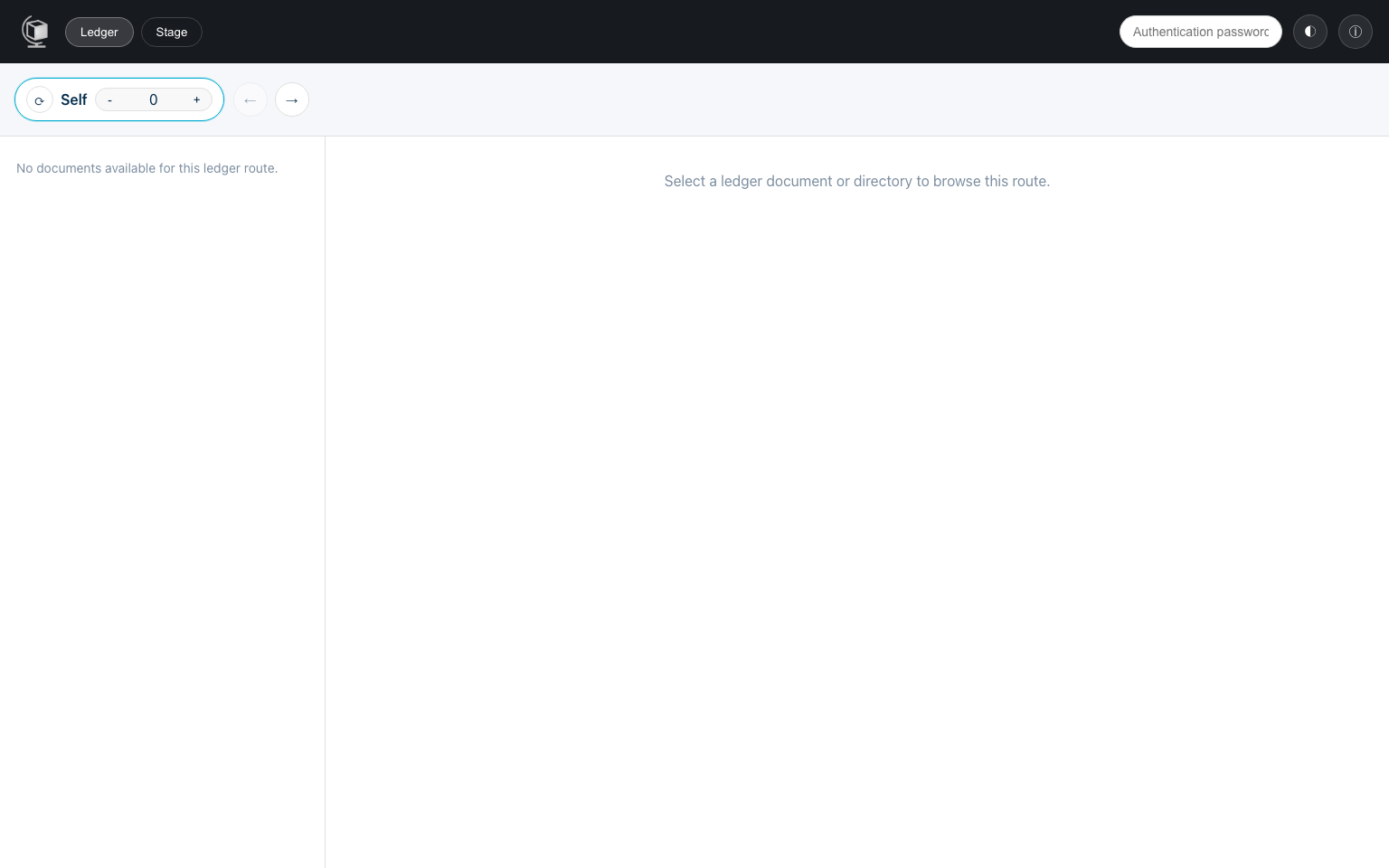
Section titled “Explorer”The Explorer is the state-navigation and content-management interface. It now has two explicit modes:
Ledger- the default landing mode
- route-based browsing of committed state across bridges and snapshots
Stage- local editable staged state
- file and directory oriented editing actions
Typical Explorer workflow:
- Start in
Ledgerand synchronize to the latest committed root. - Use the route strip to browse from
Selfthrough bridges and historical snapshots. - Select a ledger file to switch between content and proof views or pin/unpin it.
- Switch to
Stagewhen you want to edit local staged files and directories. - Use stage actions to create documents/directories, upload files, edit content, and download files.
The Explorer is best for operational tasks and data exploration because it separates committed ledger inspection from local staged editing while keeping both in one UI.
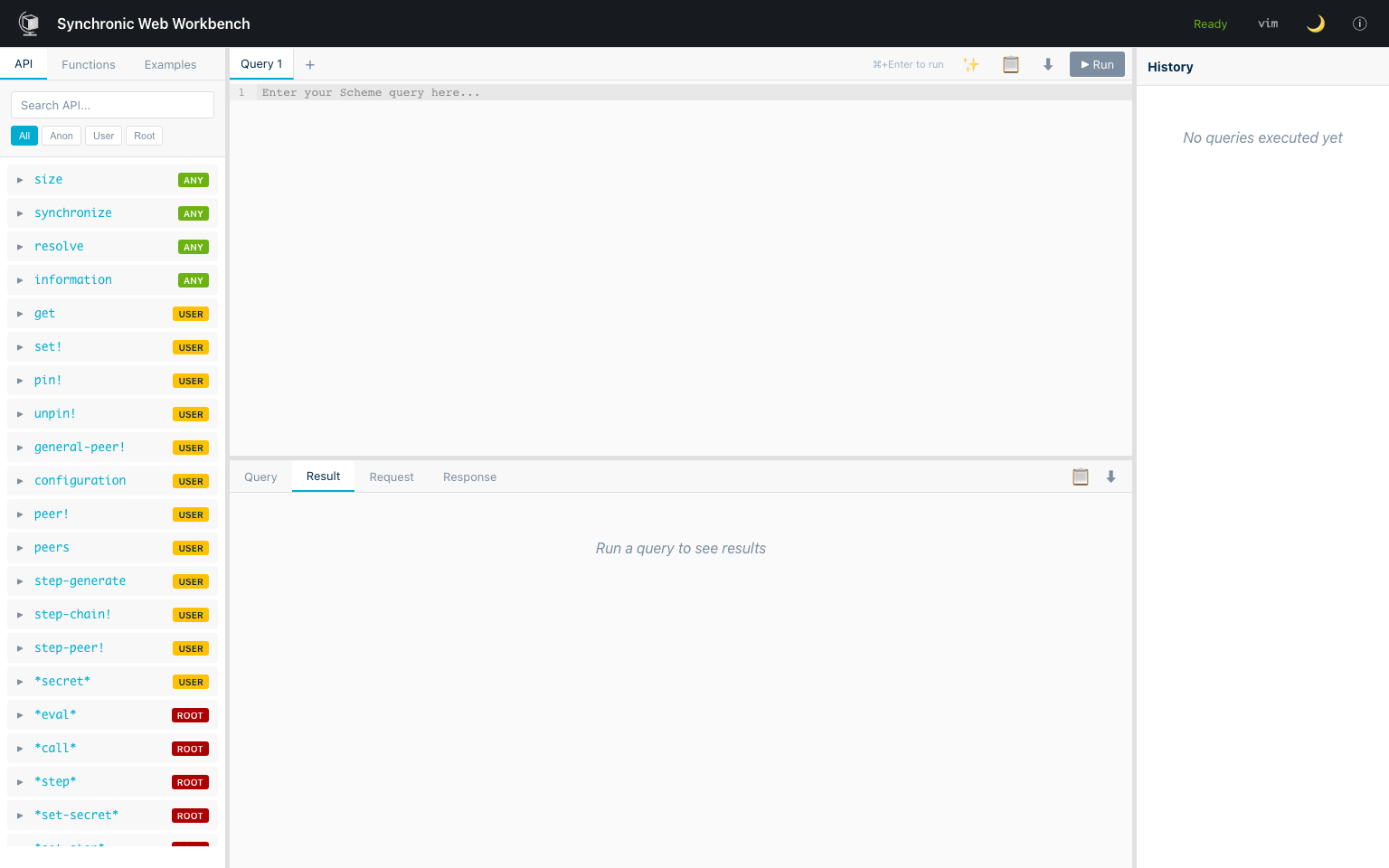
Workbench
Section titled “Workbench”The Workbench is the API-oriented query environment. Use it when you want precise control over requests, fast iteration on payload shape, and direct inspection of results.
Typical Workbench workflow:
- Start from a known request pattern (for example
get,set!,pin!, orbridge!). - Run the request in Scheme or JSON form and inspect the returned value.
- Iterate on arguments/authentication until behavior matches intent.
- Use the final request as a template for automation or service integration.
The Workbench is best for debugging and integration development because it exposes the request/response layer directly.
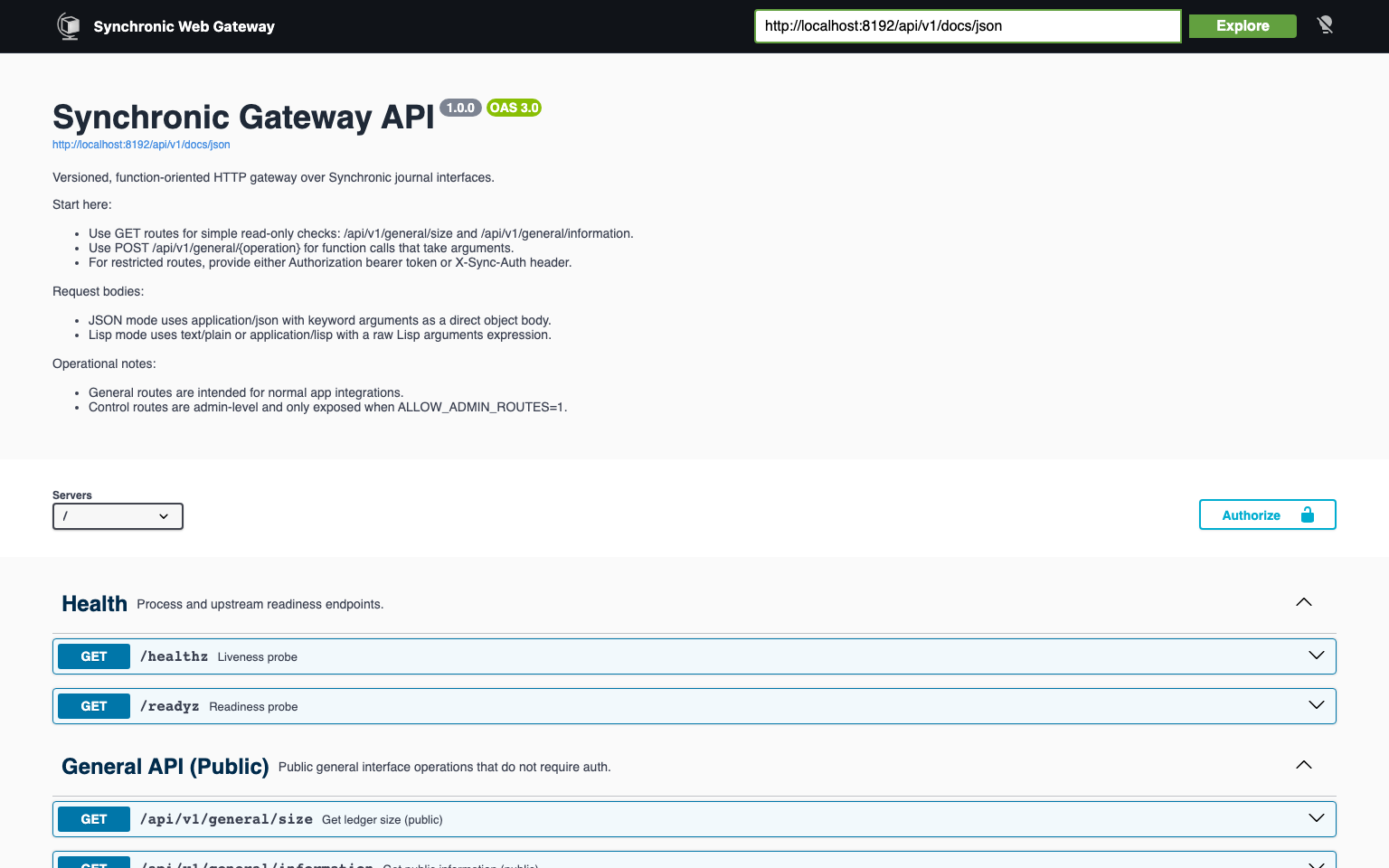
Gateway
Section titled “Gateway”The Gateway is the web-facing API surface for journal operations. Use it when clients should call stable, versioned HTTP routes instead of direct function-shaped interface requests.
Typical Gateway workflow:
- Start with
GET /docsto review request and response schemas. - Use
GET /api/v1/general/sizeor another stable route to validate connectivity. - Execute public general operations through
GETroutes (for examplesize,info, andtrace). - Execute restricted
generaland optionalcontroloperations through authenticatedPOSTroutes. - Move validated requests into application clients or automation scripts using the same gateway contracts.
The Gateway is best for service integration because it standardizes journal calls into HTTP endpoints with explicit request validation.
File System
Section titled “File System”The File System service projects journal state into a mounted SMB share. Use it when existing tools should interact with Synchronic Web data through ordinary file and directory operations instead of direct API calls.
Typical File System workflow:
- Mount the share and work in
/stagefor ordinary mutable file operations. - Browse
/ledger/statefor current committed content. - Traverse
/ledger/previous/<index>/statefor prior committed states. - Traverse
/ledger/bridge/<name>/...for recursively bridged ledger state. - Use
/control/pinfor explicit pin and unpin directives on discovered ledger paths.
The File System service is best for shell tools, editors, archives, source trees, and other workflows that already expect a hierarchical filesystem.
Filesystem projection overview:
/├── stage/│ └── ...├── ledger/│ ├── state/│ │ └── ...│ ├── previous/│ │ └── <index>/│ │ ├── state/│ │ ├── bridge/│ │ └── previous/│ └── bridge/│ └── <name>/│ ├── state/│ ├── bridge/│ └── previous/└── control/ └── pinKey semantics:
/stageis mutable./ledger/...is readable but content-immutable.- once you enter any
state/subtree, remaining path segments are ordinary file and directory names. /control/pinis a synthetic UTF-8 control file for pin and unpin directives against discovered/ledger/...paths.
Programmatic API
Section titled “Programmatic API”Programmatic access is typically where teams standardize integrations across multiple services. The sections below focus on stable request patterns that are easy to lint, test, and automate.
Endpoint Catalog
Section titled “Endpoint Catalog”Use this catalog as a quick orientation map.
The two execution endpoints (/interface, /interface/json) are for runtime calls, while the conversion endpoints are for debugging and payload authoring.
| Endpoint | Description |
|---|---|
POST /interface | Executes Scheme requests directly against the interface runtime. |
POST /interface/json | Executes JSON requests using the object-shaped API envelope. |
POST /interface/scheme-to-json | Converts Scheme expressions into JSON payload representations. |
POST /interface/json-to-scheme | Converts JSON payloads back into Scheme forms for debugging and validation. |
Request Envelope
Section titled “Request Envelope”Most JSON integrations can standardize on this envelope and only vary function and arguments.
That keeps client implementations simple and makes troubleshooting easier across services.
| Field | Type | Required | Notes |
|---|---|---|---|
function | symbol/string | Yes | API function name |
arguments | object / association list | Usually | Keyword-style fields for ledger calls |
authentication | string / *type/string* | Restricted calls | Interface secret |
Note:
In Scheme form, API queries are association lists. In JSON form, they are objects with equivalent fields.
Operation Examples
Section titled “Operation Examples”These examples are intentionally minimal and map directly to frequently used workflows. You can copy them into Workbench first, then move them into automation once validated.
Read (get)
Section titled “Read (get)”((function get) (arguments ((path ((*state* docs article hash))) (pinned? #t) (proof? #t))) (authentication "password")){ "function": "get", "arguments": { "path": [["*state*", "docs", "article", "hash"]], "pinned?": true, "proof?": true }, "authentication": {"*type/string*": "password"}}Info: When to use
pinned?andproof?Use
pinned?when you want to know whether a historical path remains pinned, and useproof?when you need the proof payload itself.
Write (set!)
Section titled “Write (set!)”((function set!) (arguments ((path ((*state* docs article hash))) (value "0xabc123"))) (authentication "password")){ "function": "set!", "arguments": { "path": [["*state*", "docs", "article", "hash"]], "value": {"*type/string*": "0xabc123"} }, "authentication": {"*type/string*": "password"}}Pin (pin!)
Section titled “Pin (pin!)”((function pin!) (arguments ((path (-1 (*state* docs article hash))))) (authentication "password")){ "function": "pin!", "arguments": {"path": [-1, ["*state*", "docs", "article", "hash"]]}, "authentication": {"*type/string*": "password"}}Bridge (bridge!)
Section titled “Bridge (bridge!)”((function bridge!) (arguments ((name journal_b) (interface "http://journal-b.example.org/interface"))) (authentication "password")){ "function": "bridge!", "arguments": { "name": "journal_b", "interface": {"*type/string*": "http://journal-b.example.org/interface"} }, "authentication": {"*type/string*": "password"}}JSON/Scheme Conversion
Section titled “JSON/Scheme Conversion”The converter treats JSON and Scheme as structurally equivalent where possible.
Core Mapping
Section titled “Core Mapping”This mapping is the key mental model for moving between web client payloads and Scheme-native request forms. Once this is clear, advanced payloads become much easier to reason about.
| Scheme | JSON |
|---|---|
| symbol | string |
| list | array |
association list ((k v) ...) | object { "k": v, ... } |
| object-shaped assoc list | object |
Special Types
Section titled “Special Types”Special type wrappers are only needed where plain JSON cannot preserve Lisp/runtime semantics. If a payload seems unexpectedly interpreted, check whether a special type marker is required.
| JSON marker | Scheme value |
|---|---|
{"*type/string*": "text"} | string |
{"*type/quoted*": ...} | (quote ...) |
{"*type/byte-vector*": "deadbeef"} | byte-vector |
{"*type/vector*": [...]} | vector |
{"*type/pair*": [a, b]} | dotted pair (a . b) |
{"*type/rational*": "1/3"} | rational |
{"*type/complex*": "1+2i"} | complex |
Practical Guidance
Section titled “Practical Guidance”Use /interface/scheme-to-json to generate exact JSON for complex expressions, and use /interface/json-to-scheme when debugging client payloads or validating round-trip conversions.
For web clients, prefer object-shaped API queries (function, arguments, authentication) because they remain easier to read and diff than raw array forms, and reserve array-shaped JSON for raw root command calls.
Prefer *type/string* for literal strings in JSON payloads whenever you need to avoid ambiguity in type conversion.
A common workflow is: prototype in Scheme, convert to JSON, integrate in client code, then round-trip with json-to-scheme during debugging.
Teams that include conversion checks in their release process generally catch payload-shape regressions earlier.