Incident Response Workflow
The Incident Response workflow is focused on responding and remediating cyber security events. Those events may originate from detection systems or human reporting. Below we will work through the IR workflow. The data displayed is Faker data, so use your imagination to envision what real cyber security data and investigation results could look like.
Alerts and Alertgroups
The Incident Response (IR) workflow begins with triaging the Alerts Queue. Alerts flow into the Alerts queue in groups called Alertgroups.
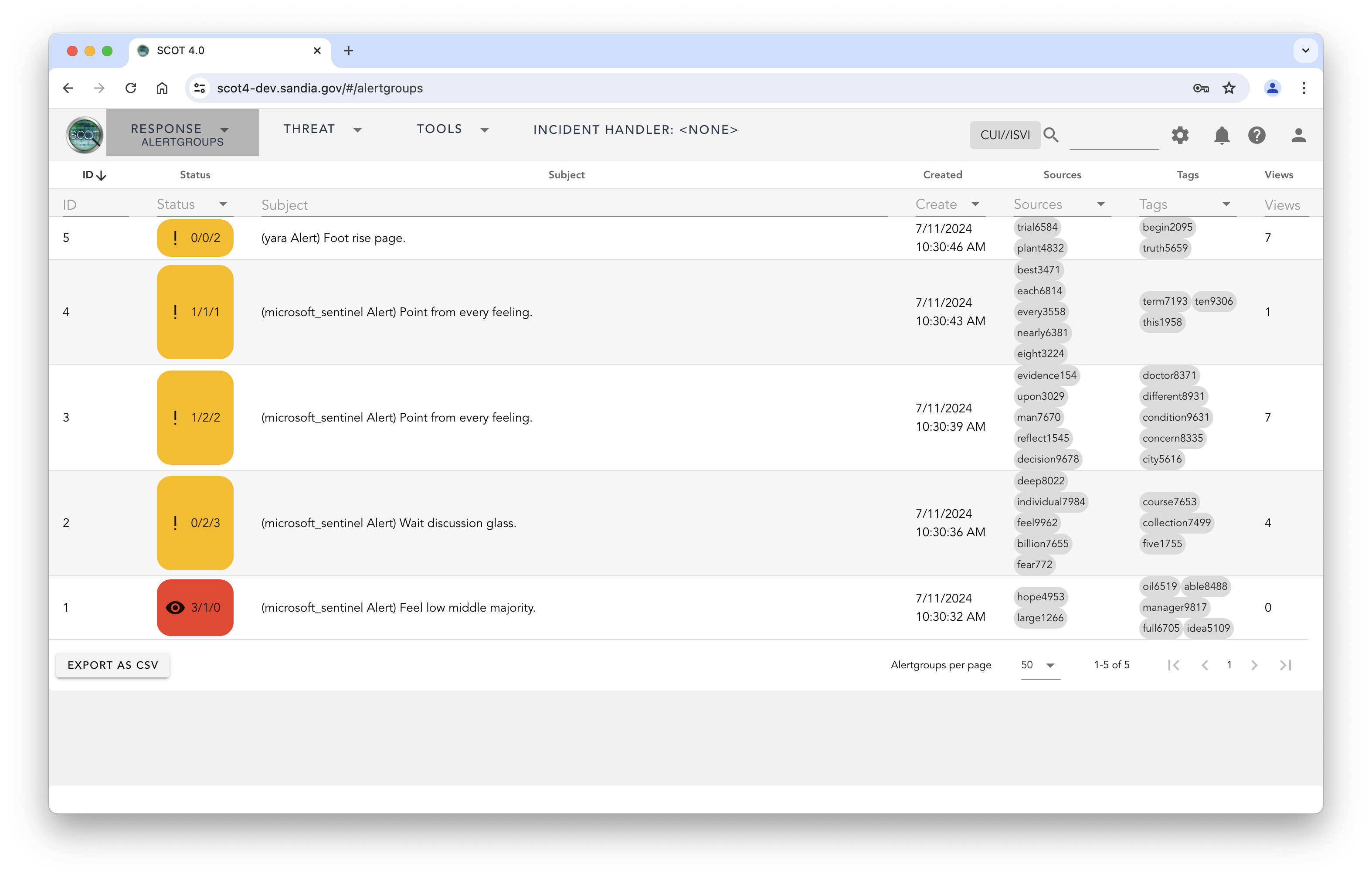
Each team using SCOT can develop their own stategy for processing the Alertgroup queue, as SCOT attempts to stay out of your way and does not proscribe a “one true way” of doing IR. Below, however, is an example of a way that works for us.
The incident response team (IRT) has one or more “Incident Handers” (IH) defined in the IH calendar (/#/team/calendar). IH’s primary role is to examine and triage this incoming flow of alerts. Many alerts are easily recognized as normal or non-threatening. The IH can rapidly close these alerts as a signal to the rest of the team not to waste their time on them.
Some alerts require more scrutiny though. One option is to leave an Alert “open” so that other members of the team or the other IHs can look at the alert while further investigation of the alert is on-going. A possibly better option, is to to promote the Alert to an Event. This promotion is a signal to the IRT that we have something that needs the team’s help in investigating.
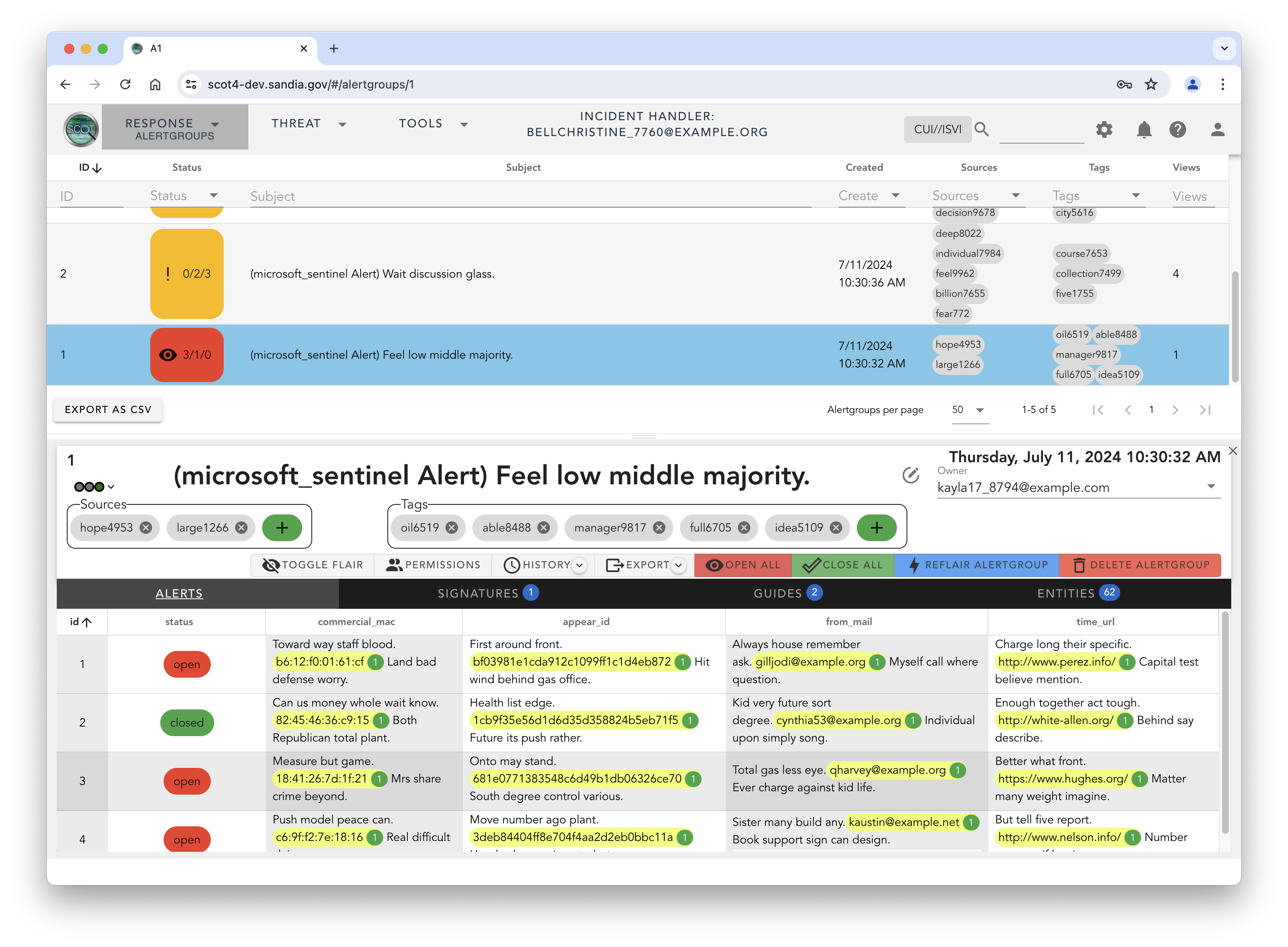
Events
Events are designed to coordinate the IRT’s activities, collect and retain the information developed during the investigation, and serve as a record of actions taken. As the team begins investigating the Event, they record their activities and findings as threaded sequence of Entries. Entries are HTML text sections designed to hold the results of the other investigative systems. For example, if the IRT member looks up the DNS record of an IP address that appears in the Event, they can store the results within an Entry.
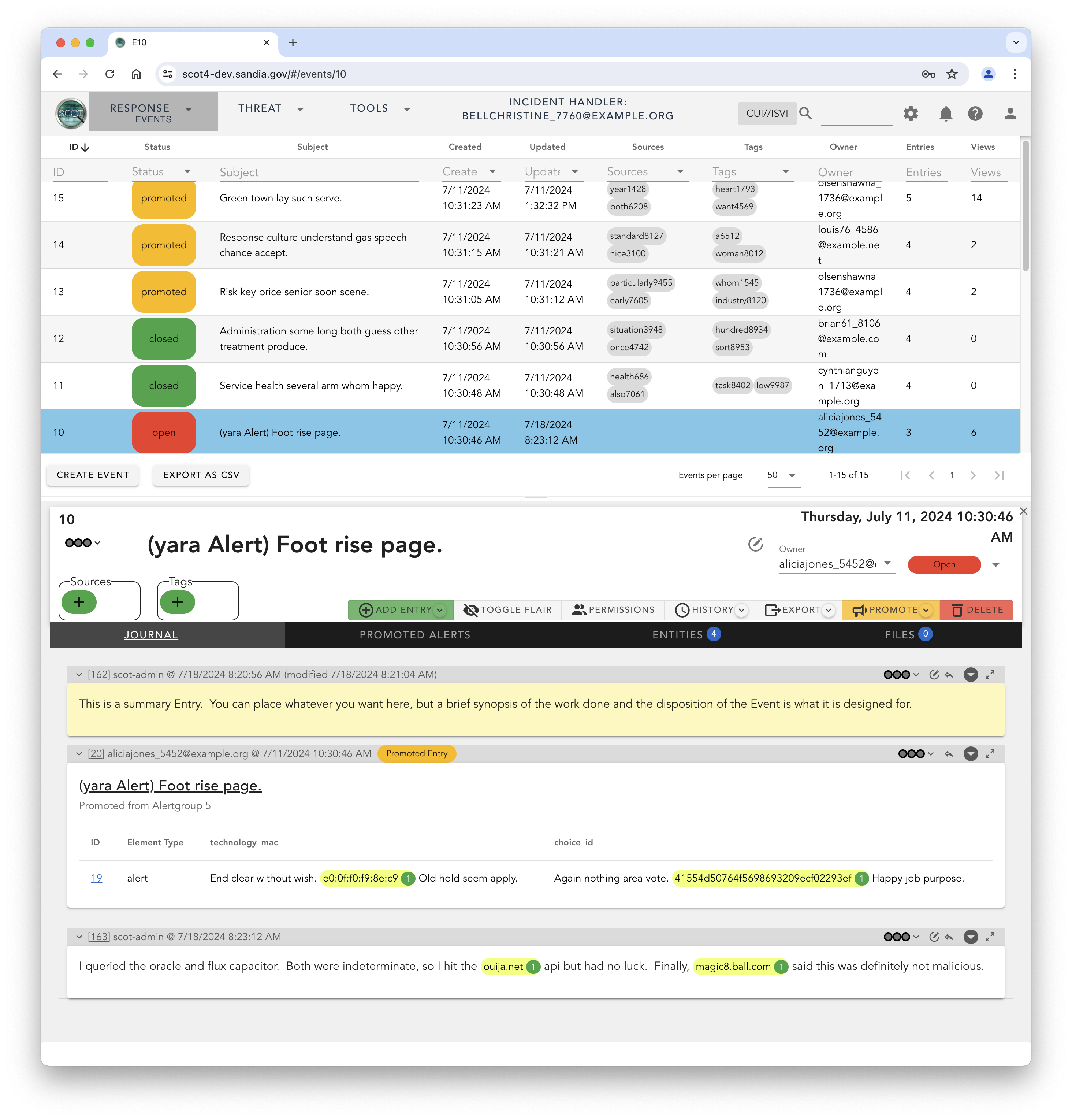
Storing these results in the Entry benefits the entire team. It prevents duplicative work. Other team members no longer have to re-investigate items and can focus their efforts in other unexplored areas of investigation. Entries also allow the gradual building of a record of activities that can be easily used as source material for a more formal report. As the Event becomes understood by the team, summary Entries are added which are useful for managers and others wanting to rapidly learn the disposition of the Event.
Incidents
The lifecycle of an event leads to its eventual closure or promotion to an Incident. Closing and event, signifies that the active phase of investigation is closed and no other significant activity on the event is expected. Events can be added to and modified even if closed, however. This is part of the SCOT philosophy to not proscribe behaviors through artificial workflow controls. In fact, anything that has been closed can easily be reopened.
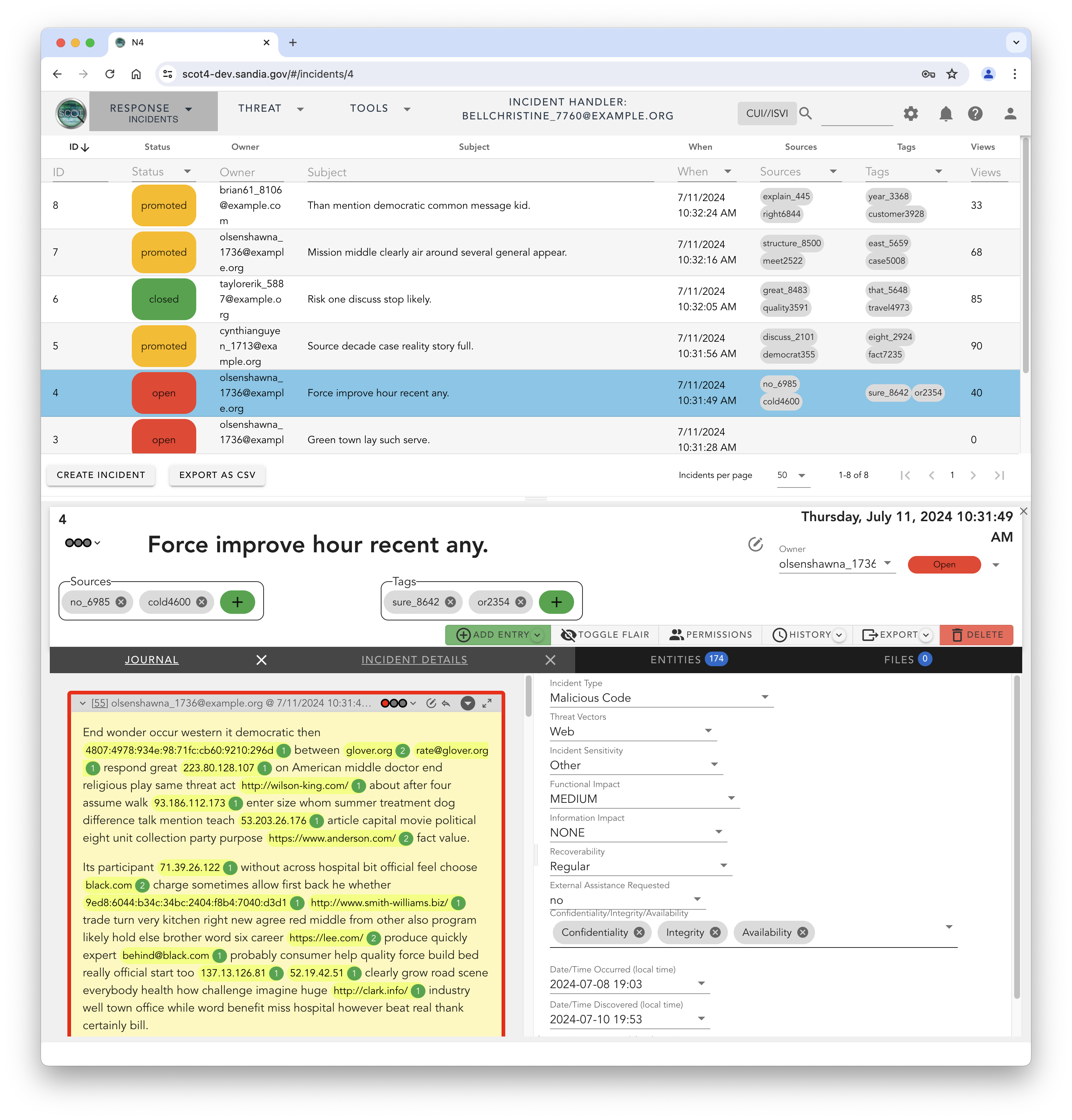
An Incident is a flexible concept with in SCOT and it is expected that you will develop your own heuristic for what constitutes an Incident. Some teams may have a contractual reporting requirement, and Incidents make a convenient construct to track those formal reports. For other teamss may just use Incidents as grouping of Events related to a particular campaign. Either way, multiple Events can be promoted into a single Incident. Entries can be attached to the Incident to track your reporting compliance, or to hold the final report of the cyber attack and the remediation activities.
At the end of this workflow, you have a valuable archive that details the activities and lessons learned by the team. This knowledge can be used to great effect to engineer better detections, identify attacher patterns, and to educate new IRT members. It also acts as an organizational memory so that tribal knowledge does not walk out the door with personnel changes.
Tuning
Each organization will likely have differing capabilities with regards to team size and detection systems. The temptation is to thow every alert possible into SCOT. This approach presents several challenges. Most importantly, this approach will swamp your IHs and “train” them to ignore a some alerts to focus on what they consider to be more important alerts. The net result is a bigger Haystack to look through which means some alerts will never get looked at.
If you do plan to start with all alerts appearing in SCOT, be sure to have a process in place to rapidly tune your detection systems to filter out common false positives and non-actionable alerts. SCOT can help build this virtuous cycle, by allowing the tagging of alerts, events, and other items. IRT members can tag items with “falsepositive”, or “benign_behavior”, etc. Regular meetings can be held, and alerts and events with these tags can be examined and plans for detection tuning can be implemented. Signatures are particularly useful construct for this activity. Attaching entries to the Signatures, allows the team to document the how’s and why’s of changes made to detection systems.
A couple of experienced IHs can triage around a thousand or so alerts a day. Burnout can be a problem, so be sure to rotate your IHs! Of those alerts, maybe 10 to 20 become events. Of every 100 events, one rises to be incident. This is the Funnel, where we see a great reduction of items at each level. These numbers will vary with the administrative practices your team develops using SCOT and refining your incident response process.