Replicating Online Resources
This guide helps users whom need to download online data and software for their experiments. That is, how can users archive data/software from online services to then use in an offline environment. While this topic is complex and entirely depends on what the needed resource is, this guide should help answer the following questions:
What are common issues when replicating environments offline?
How should we gather system packages to use as a VM Resource?
Are there tools available for this process?
Common Issues
Computers interact with numerous online services daily. This includes getting OS updates, downloading new configuration policies, visiting websites, etc. However, when creating an Emulytics experiment, any services necessary for the experiment need to be replicated. To reduce the experimental complexity (and risk of introducing errors), we always recommend starting with the smallest viable experiment.
Even when starting small, to ensure a successful experiment, VMs will likely need new software and various configuration changes, all while remaining offline. Here are a few common issues when retrieving software for use in an Emulytics experiment.
Using Mismatched OS Versions
If a given VM in an experiment needs a software package, it’s best to use the exact same VM image used by FIREWHEEL to download and archive the package.
This is especially important when installing system or OS packages with numerous dependencies.
Many times the package managers know the exact version needed for the VMs patch-level and which dependencies are missing.
For example, if you want to compile some software within a Ubuntu VM, you might need the build-essential package.
However, if the image from where you are collecting other needed packages already has it installed, the various *.deb files from build-essential might be missed.
It is a painful experience to start an experiment only to realize that it failed because of a missing dependency.
Forgetting Dependencies
Related to issues of using mismatched OS versions, which can result in system packaged managers (e.g. apt) neglecting to pull necessary dependencies, users can also forget to collect ALL dependencies for the desired software. For example, Python packages can easily be downloaded via https://pypi.org/ or https://github.com/ but users must remember that all of the Python package dependencies will also be needed.
Dynamic Calls to Online Services
In some cases, software may need to download additional content that might not be initially obvious. Here are a few common examples of this issue:
An extension is needed for a specific software feature.
Software needing a response from an online API before proceeding.
Network-based installers. These might be smaller to download, but then when executed pull more data from the Internet.
To avoid these issues, it’s best to actually practice installing the software via an offline VM to understand it’s needs prior to using it in your FIREWHEEL experiment.
Collecting Packages
This section provides tips on collecting packages for various systems.
Note
There are likely other ways of accomplishing the same goals. We are happy to accept suggestions and/or improvements to these methods.
Ubuntu Debian Packages
To install a collection of debian packages in a FIREWHEEL experiment, users can simply call the install_debs method (assuming that their VM has been decorated as a linux.ubuntu.UbuntuHost).
However, how users need to first collect all the necessary packages.
First, we recommend starting an Internet-accessible VM using the exact same image that will be used in FIREWHEEL (see VM Builder for an example).
Once the VM is started, you can follow the following steps:
Clear out
/var/cache/apt/archivesof any remaining.debfiles. This ensures that you only save off files that were not previously available to the VM.$ sudo rm -f /var/cache/apt/archives/*.deb
That directory should now look similar to:

Install the necessary packages using
apt-get install.Warning
This method will not work if the packages are installed with
apt install! Additionally, similar methods like usingapt-get downloadorapt-get install --download-onlywill only download the specific package, not any dependencies.$ # In this example, we will install curl $ sudo apt-get install curl
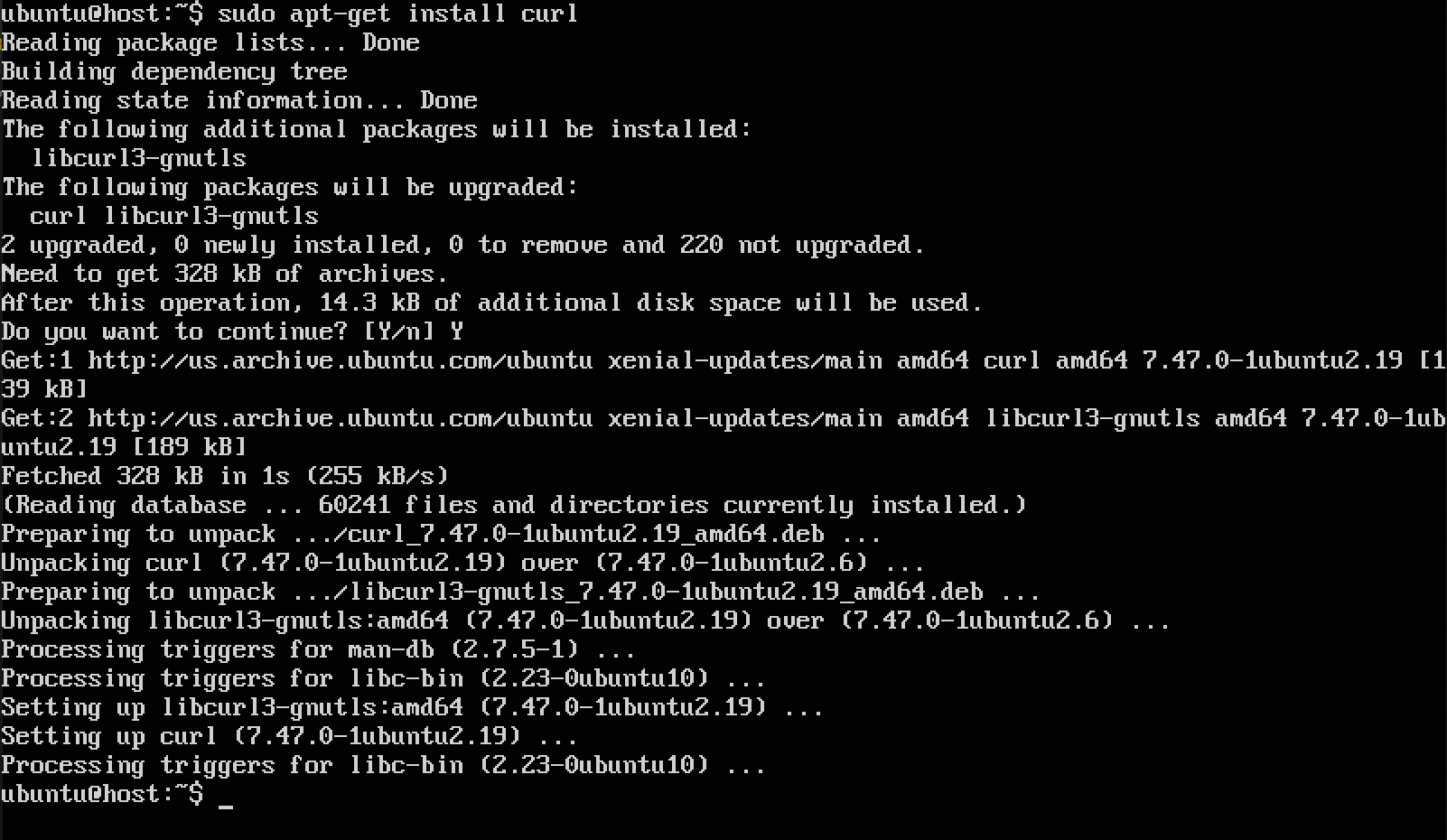
The installed
.debfiles and all installed dependencies/updates will now be located in/var/cache/apt/archives.
Create a directory in the home folder and copy all
.debfiles into that directory.$ mkdir curl_debs $ sudo cp /var/cache/apt/archives/*.deb curl_debs/

Compress the folder and copy it off of the VM.
$ tar -czvf curl_debs.tgz curl_debs

Now you are ready to use the generated tarball as a VM resource.
That is, you can move it to your Model Components directory and add it to the MANIFEST file.
Then, in your Plugin or Model Component Objects file, you can call the install_debs method.
# Example of using the newly created VM Resource vm = Vertex(self.g, "example-vm") vm.decorate(Ubuntu1604Server) vm.install_debs(-5, "curl_debs.tgz")
Alternative Approaches:
Using apt-offline.
CentOS RPM Packages
While CentOS and RHEL do not currently have any related Model Components [1], we have had success using yumdownloader to download RPM packages and their dependencies.
See also
We have found these tutorials helpful in downloading RPMs for offline use:
Tools to Help
The vm builder Helper is a key part of collecting packages for a specific VM image. For a separate tutorial on using VM Builder, please see VM Builder.